3. Linux Çekirdeğinde Bağlı Listeler ve Hash Tabloları
Bu bölümde Linux çekirdeğindeki bağlı listelerin ve hash tablolarının gerçekleştirimleri üzerinde duracağız. Çekirdeğin diğer önemli veri yapıları onların kullanıldığı konular ele alınırken açıklanacaktır.
3.1. Bağlı Listeler
Çekirdeğin en önemli veri yapılarından biri bağlı listelerdir. Genel olarak çekirdekteki neredeyse tüm bağlı listeler çift bağlı (doubly linked) biçimde kullanılmaktadır. Önce bağlı listelerin Linux çekirdeğindeki gerçekleştirimleri üzerinde duracağız.
Aralarında öncelik-sonralık ilişkisi olan veri yapılarına liste (list) tarzı veri yapıları denilmektedir. Örneğin bu tanıma göre diziler de “liste tarzı” veri yapılarıdır. Liste tarzı veri yapılarının en yaygın kullanılanlarından biri bağlı liste (linked list) denilen veri yapısıdır. Önceki elemanın sonraki elemanın yerini gösterdiği dolayısıyla elemanların ardışıl olma zorunluluğunun ortadan kaldırıldığı listelere “bağlı liste” denilmektedir. Dizi elemanlarının bellekte fiziksel olarak ardışıl biçimde bulunduğunu anımsayınız. Bağlı listeler adeta “elemanları bellekte ardışıl olmak zorunda olmayan diziler” gibidir.
Bağlı listelerin her elemanına düğüm (node) denilmektedir. Bağlı listelerde her düğüm sonraki düğümün yerini tuttuğuna göre ilk elemanın yeri biliniyorsa liste elemanlarının hepsine erişilebilmektedir:

Her düğümün yalnızca sonraki düğümün değil aynı zamanda önceki düğümün yerini de tuttuğu bağlı listelere çift bağlı listeler (doubly linked lists) denilmektedir. Çift bağlı listelerde belli bir düğümün adresini biliyorsak yalnızca ileriye doğru değil, geriye doğru da gidebiliriz:
Çift bağlı listelere ilişkin bir düğümün bellekte daha fazla yer kaplayacağına dikkat ediniz. Çift bağlı listelerin tek bağlı listelere göre en önemli özelliği “adresi bilinen bir düğümün” silinebilmesidir. Tek bağlı listelerde bu durum mümkün değildir. Uygulamalarda ve özellikle çekirdek kodlarında buna çok sık gereksinim duyulmaktadır.
Eğer bir bağlı listede son eleman da ilk elemanı gösteriyorsa bu tür bağlı listelere döngüsel bağlı listeler (circular linked lists) denilmektedir.
3.2. Bağlı Listelere Neden Gereksinim Duyulmaktadır?
Peki bağlı listelere neden gereksinim duyulmaktadır? Diziler varken bağlı listelere gerek var mıdır? Dizilerle bağlı listeler arasındaki farklılıkları, benzerlikleri ve bağlı listelere neden gereksinim duyulduğunu birkaç maddede açıklayabiliriz:
Bellek parçalanması sorunu: Diziler ardışıl alana gereksinim duymaktadır. Ancak belleğin bölündüğü (fragmente olduğu) durumlarda bellekte yeteri kadar küçük boş alanlar olduğu halde bunlar ardışıl olmadığı için dizi tahsisatı mümkün olamamaktadır. Bu tür durumlarda ardışıllık gereksinimi olmayan bağlı listeler kullanılabilir. Özellikle heap gibi bir alanda çok sayıda dinamik dizi bellek kullanımı bakımından verimsizliğe yol açabilmektedir. Bu dinamik diziler zamanla büyüdükçe birbirini engeller hale gelebilmektedir. İşte uzunluğu baştan belli olmayan çok sayıda dizinin oluşturulacağı durumlarda dinamik diziler yerine bağlı listeler bellek kullanımı bakımından toplamda daha iyi performans gösterebilmektedir. Dinamik dizilerde büyütme sırasında bloklar yer değiştirebileceği için bu işlem yavaştır.
Araya ekleme ve silme verimliliği: Dizilerde araya eleman ekleme (insert etme) ve aradaki bir elemanı silme dizinin kaydırılmasına yol açacağından yavaş bir işlemdir. Teknik olarak dizilerde eleman insert etme ve eleman silme O(N) karmaşıklıkta bir işlemdir. Halbuki bağlı listelerde eğer düğümün yeri biliniyorsa bu işlem O(1) karmaşıklıkta (yani döngü olmadan tekil işlemlerle) yapılabilmektedir. O halde araya eleman eklemenin ve aradan eleman silmenin çok yapıldığı sistemlerde diziler yerine bağlı listeler tercih edilebilmektedir. Çekirdek veri yapılarında araya eleman ekleme ve aradan eleman silme gibi işlemler çok yoğun yapılmaktadır.
İndeksle erişim yavaşlığı: Bağlı listelerde belli bir indeksteki elemana erişmek O(N) karmaşıklıkta bir işlemdir. Halbuki dizilerde elemana erişim O(1) karmaşıklıkta yani çok hızlıdır. O halde belli bir indeks değeri ile elemana erişimin yoğun yapıldığı durumlarda bağlı listeler yerine diziler tercih edilmelidir.
Bağlı listeler toplamda bellekte daha fazla yer kaplama eğilimindedir. Çünkü bağlı listenin her düğümü sonraki (ve duruma göre önceki) elemanın yerini de tutmaktadır.
O halde bağlı listeler tipik olarak şu durumlarda dizilere tercih edilmelidir:
Eleman insert etmenin ve eleman silmenin sık yapıldığı durumlarda.
Uzunluğu baştan belli olmayan çok sayıda dizinin kullanıldığı durumlarda.
İndeks yoluyla erişimin az yapıldığı durumlarda.
Toplam bellek miktarının yeteri kadar fazla olduğu sistemlerde.
İşte tüm yukarıdaki nedenlerden dolayı bağlı listeler çekirdek için en önemli veri yapılarından biridir.
3.3. Linux Çekirdeğindeki Bağlı Liste Gerçekleştirimi
Linux çekirdeğinde bağlı liste gerçekleştirimi include/linux/list.h dosyasında yapılmıştır. Bu dosya
içerisindeki fonksiyonlar static inline biçiminde tanımlanmıştır. Çekirdek derlemesi sırasında
derleyicinin optimizasyon seçeneği ayarlandığı için derleyici buradaki inline fonksiyonları sanki bir makro
gibi koda açmaktadır.
Linux çekirdeğindeki bağlı listelerde düğümler list_head isimli bir yapıyla temsil edilmektedir:
struct list_head {
struct list_head *next;
struct list_head *prev;
};
Aslında belli yapılar değil, bu list_head yapıları bağlı liste içerisinde birbirine bağlanmaktadır:
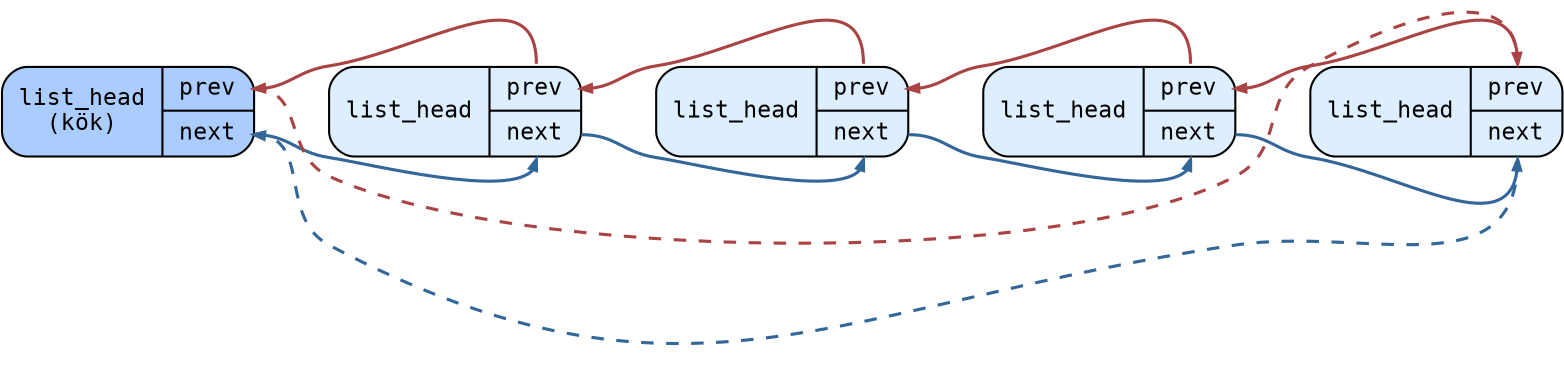
Tabii eğer bu list_head yapıları başka bir yapının (buna asıl yapı diyelim) içerisindeyse bu durumda
aslında bir list_head yapısının adresi asıl yapının bir elemanının adresi haline gelmektedir. Biz C’de
bir yapının bir elemanının adresini biliyorsak kolaylıkla o yapının başlangıç adresini elde edebiliriz.
Çünkü yapı elemanları ardışıldır ve standart offsetof makrosuyla belli bir yapı elemanının yapının
başlangıcından itibaren hangi offset’te bulunduğu bilgisi elde edilebilmektedir. offsetof makrosu
<stddef.h> içerisinde aşağıdakine benzer biçimde tanımlanmıştır:
#define offsetof(type, member) ((size_t)&(((type *)0)->member))
offsetof makrosunun birinci parametresi yapının tür ismini, ikinci parametresi ilgili yapı elemanının
ismini almaktadır. Tabii offsetof makrosu yalnızca size_t türünden bir byte offset’i vermektedir.
Elemanın adresinin makroyla elde edilen bu değerden çıkartılarak tür dönüştürmesinin yapılması gerekir.
İşte bunun için Linux çekirdeğinde container_of isimli bir makro bulundurulmuştur. Bu makronun basit
yazımı şöyle yapılabilir:
#define container_of(ptr, type, member) ((type *)((char *)ptr - myoffsetof(type, member)))
container_of makrosunun birinci parametresi yapı elemanının adresini, ikinci parametresi yapının tür
ismini ve üçüncü parametresi de ilgili yapı elemanının ismini almaktadır. Bu makro ikinci parametresine
girilmiş olan yapı türünden bir adres vermektedir.
container_of makrosunu list_entry ismiyle de kullanabilirsiniz:
#define list_entry(ptr, type, member) container_of(ptr, type, member)
3.3.1. Bağlı Listenin Başlatılması
Linux çekirdeğindeki bağlı listeler kullanılırken önce bir başlangıç düğümünün oluşturulması gerekir.
Başlangıç düğümünde next ve prev göstericilerinin başlangıç düğümünün kendisini göstermesi
gerekir. Örneğin:
struct list_head head = {&head, &head};
Bu ilkdeğer verme C’de geçerlidir. Çünkü C’de bir değişken faaliyet alanına = atomu ile ilkdeğer
verme kısmından önce sokulmaktadır. list.h dosyasında bu işlemi yapan aşağıdaki gibi bir makro da
bulundurulmuştur:
#define LIST_HEAD_INIT(name) {&(name), &(name)}
Bu durumda başlangıç düğümü bu makroyla şöyle de oluşturulabilir:
struct list_head head = LIST_HEAD_INIT(head);
Aslında bu tanımlamanın tamamını yapan aşağıdaki gibi bir makro da bulundurulmuştur:
#define LIST_HEAD(name) \
struct list_head name = LIST_HEAD_INIT(name)
O halde biz başlangıç düğümünü basit bir biçimde şöyle oluşturabiliriz:
LIST_HEAD(head);
Linux’un bağlı liste gerçekleştiriminde next ve prev göstericilerinde NULL adres
kullanılmamıştır. Son düğümün next göstericisi NULL yerine başlangıç düğümünü, ilk düğümün
prev göstericisi de NULL yerine son düğümü göstermektedir. Yani aslında bağlı liste
gerçekleştirimi döngüsel (circular) gibidir. Herhangi bir düğümden başlanarak başlangıç düğümü de
atlanırsa tam dolaşım sağlanabilir. Bağlı listenin başlangıç düğümünün prev göstericisi de son
düğümü göstermektedir.
3.3.2. Düğüm Ekleme
Bağlı listenin başına list_head düğümünü eklemek için list_add fonksiyonu kullanılmaktadır:
static inline void list_add(struct list_head *new, struct list_head *head)
{
__list_add(new, head, head->next);
}
Fonksiyonun birinci parametresi eklenecek düğümün adresini, ikinci parametresi başlangıç düğümünün adresini almaktadır.
Çekirdek kodlarında iki alt tire ile başlayan fonksiyonlar aşağı seviyeli fonksiyonlardır. Yani doğrudan
çağrılmayan ancak başka fonksiyonların içerisinden dolaylı biçimde çağrılan fonksiyonlardır. Buradaki
__list_add fonksiyonu şöyle yazılmıştır:
static inline void __list_add(struct list_head *new,
struct list_head *prev,
struct list_head *next)
{
if (!__list_add_valid(new, prev, next))
return;
next->prev = new;
new->next = next;
new->prev = prev;
WRITE_ONCE(prev->next, new);
}
Buradaki WRITE_ONCE makrosu atama işlemini volatile erişimle yapmaktadır. WRITE_ONCE(a, b)
çağrısını şimdilik a = b gibi düşünebilirsiniz.
Bağlı listenin sonuna düğüm eklemek için list_add_tail fonksiyonu kullanılmaktadır:
static inline void list_add_tail(struct list_head *new, struct list_head *head)
{
__list_add(new, head->prev, head);
}
3.3.3. Bağlı Listenin Dolaşılması
Peki biz bağlı listeyi nasıl dolaşabiliriz? Başlangıç düğümünü geçerek sürekli ileriye gidersek son düğüm de başlangıç düğümünü gösterdiğine göre dolaşımı aşağıdaki gibi bir for döngüsüyle yapabiliriz:
struct list_head *lh;
for (lh = head.next; lh != &head; lh = lh->next) {
/* ... */
}
Tabii böyle bir döngüde dolaşım yapılırken aslında biz her yinelemede ilgili yapının başlangıç adresini
değil list_head yapısının başlangıç adresini elde ederiz. container_of makrosu ile bu adresin
yapı adresine dönüştürülmesi gerekir. Örneğin biz struct SAMPLE türünden yapı nesnelerini birbirine
bağlamış olalım:
LIST_HEAD(head);
struct SAMPLE {
int a;
struct list_head link;
};
Eklemeleri şöyle yapmış olalım:
struct SAMPLE *ps;
for (int i = 0; i < 10; ++i) {
if ((ps = (struct SAMPLE *)malloc(sizeof(struct SAMPLE))) == NULL) {
fprintf(stderr, "cannot allocate memory!...\n");
exit(EXIT_FAILURE);
}
ps->a = i;
list_add_tail(&ps->link, &head);
}
Not
Çekirdek kodlarında malloc gibi kullanıcı modu fonksiyonları kullanılamaz. Ancak burada yalnızca anlaşılır bir test örneği verilmektedir.
struct SAMPLE yapımızdaki link elemanı list_head yapılarını birbirine bağlamak için
bulundurulmuştur. Örneğimizdeki list_add_tail fonksiyonunda ekleme yapılacak düğümün SAMPLE
yapısının içerisindeki link elemanının adresi olduğuna dikkat ediniz. Şimdi dolaşımı şöyle
yapabiliriz:
struct SAMPLE *ps;
struct list_head *lh;
for (lh = head.next; lh != &head; lh = lh->next) {
ps = container_of(lh, struct SAMPLE, link);
/* ... */
}
Burada artık ps göstericisi list_head nesnesini değil struct SAMPLE nesnesini göstermektedir.
Aslında list.h dosyası içerisinde buradaki döngüyü oluşturan list_for_each isimli bir makro da
bulundurulmuştur:
static inline int list_is_head(const struct list_head *list,
const struct list_head *head)
{
return list == head;
}
#define list_for_each(pos, head) \
for (pos = (head)->next; !list_is_head(pos, (head)); pos = pos->next)
Makronun birinci parametresi list_head türünden bir göstericiyi, ikinci parametresi başlangıç
düğümünün adresini almaktadır. Döngünün her yinelenmesinde bu göstericiye sonraki düğümün list_head
adresi atanmaktadır. Örneğin:
struct list_head *lh;
list_for_each(lh, &head) {
ps = container_of(lh, struct SAMPLE, link);
printf("%d\n", ps->a);
}
Aslında çekirdekteki list.h dosyası içerisinde yukarıdaki dolaşımı tek hamlede yapan
list_for_each_entry isimli bir makro da bulunmaktadır:
#define list_for_each_entry(pos, head, member) \
for (pos = list_first_entry(head, typeof(*pos), member); \
!list_entry_is_head(pos, head, member); \
pos = list_next_entry(pos, member))
Makronun birinci parametresi asıl yapı türünden bir göstericidir; makro her yinelemede bu göstericiye
sonraki düğümün adresini yerleştirmektedir. Makronun ikinci parametresi başlangıç düğümünün adresini,
üçüncü parametresi ise yapı içerisindeki list_head elemanın ismini belirtmektedir. Bu makronun
eşdeğeri bazı ayrıntılar ihmal edilerek şöyle de yazılabilir:
#define my_list_for_each_entry(pos, head, member) \
for (pos = container_of((head)->next, typeof(*pos), member); &(pos)->member != head; \
pos = container_of((pos)->member.next, typeof(*pos), member))
Not
C standartlarında bir ifadenin türünü veren bir tür belirleyicisi yoktu. C++’a C++11 ile birlikte
decltype ismi ile böyle bir belirleyici eklendi. gcc derleyicileri uzun süredir bu işi yapan
typeof isimli belirleyiciyi desteklemektedir. Nihayet C’ye de C23 ile birlikte resmi olarak
typeof belirleyicisi eklenmiştir. Makroda türün typeof(*pos) ifadesiyle elde edildiğine dikkat
ediniz.
Bu makro ile dolaşım şöyle sağlanabilir:
struct SAMPLE *ps;
list_for_each_entry(ps, &head, link) {
/* ... */
}
Tüyo
Bağlı liste makrolarının ve fonksiyonlarının isimlerinin sonunda entry sözcüğü varsa bu makro ya da
fonksiyon asıl yapıya ilişkin adres, yoksa list_head türünden adres verip almaktadır.
Ayrıca list.h içerisinde list_for_each_entry_safe isimli bir döngü makrosu da
bulundurulmuştur. Bu makro eğer liste boşsa hiç dolaşım yapmamaktadır. Makro aşağıdaki gibi
yazılmıştır:
#define list_for_each_entry_safe(pos, n, head, member) \
for (pos = list_first_entry(head, typeof(*pos), member), \
n = list_next_entry(pos, member); \
!list_entry_is_head(pos, head, member); \
pos = n, n = list_next_entry(n, member))
Makronun birinci elemanı dolaşımda kullanılacak asıl yapı türünden göstericiyi almaktadır. Makronun ikinci parametresi de asıl yapı göstericidir. Üçüncü ve dördüncü parametreler sırasıyla kök düğümün adresi ve bağ düğümünün ismini almaktadır.
3.3.4. Bağlı Listeden Düğüm Silme
Bağlı listeden bir düğümü silmek için list_del fonksiyonu kullanılmaktadır. Fonksiyon şöyle
tanımlanmıştır:
static inline void __list_del(struct list_head *prev, struct list_head *next)
{
next->prev = prev;
WRITE_ONCE(prev->next, next);
}
static inline void __list_del_entry(struct list_head *entry)
{
if (!__list_del_entry_valid(entry))
return;
__list_del(entry->prev, entry->next);
}
static inline void list_del(struct list_head *entry)
{
__list_del_entry(entry);
entry->next = LIST_POISON1;
entry->prev = LIST_POISON2;
}
Fonksiyonun parametresi silinecek düğüme ilişkin list_head nesnesinin adresini almaktadır. Burada
silinen düğümdeki next ve prev göstericilerine özel bazı değerlerin atandığını görüyorsunuz. Bu
değerler silinmiş düğümün kullanılması durumunda page fault oluşmasına yol açmaktadır; dolayısıyla bir
çeşit debug mekanizması oluşturmak amacıyla atandıklarını söyleyebiliriz.
3.3.5. Bağli Listede Araya Düğüm Ekleme
Bağlı listenin arasına düğüm ekleyen ayrı bir insert fonksiyonu yoktur. Zaten list_add fonksiyonu
araya ekleme işlemini de yapmaktadır. Örneğin biz araya şöyle ekleme yapabiliriz:
list_add(&ps->link, &ps_insert->link);
Burada ps eklenecek düğümün asıl yapı adresini, ps_insert ise önüne eklemenin yapılacağı asıl
yapı adresini belirtmektedir.
3.3.6. Bağli Listelerin Yok Edilmesi
Bir bağlı listeyi tümden serbest bırakmak için düğümlerin tek tek serbest bırakılması gerekmektedir. Buradaki düğümler aslında başka yapıların içerisinde olduğuna göre liste içerisindeki o yapı nesnelerinin serbest bırakılması gerekir.
3.3.7. Bağlı Listelere RCU Desteği
Belli bir süreden sonra list.h dosyasına RCU (Read-Copy-Update) mekanizmasını destekleyecek biçimde
dolaşım yapan list_for_each_rcu isimli makro da eklenmiştir. Bu makro bir yazıcı varsa okuyucuları
bekletmeden işlem yapabilmeyi sağlamaktadır. Read-Copy-Update mekanizması ileride ele alınacaktır.
3.4. Çekirdek Bağlı Listelerinin Örnek Gerçekleştirimi
Aşağıda kullanıcı alanında çekirdekteki bağlı liste kullanımına bir örnek verilmiştir.
#include <stdio.h>
#include <stdlib.h>
#include <stddef.h>
struct list_head {
struct list_head *next, *prev;
};
#define LIST_HEAD_INIT(name) { &(name), &(name) }
#define LIST_HEAD(name) \
struct list_head name = LIST_HEAD_INIT(name)
#define container_of(ptr, type, member) ({ \
void *__mptr = (void *)(ptr); \
((type *)(__mptr - offsetof(type, member))); })
#define list_entry(ptr, type, member) \
container_of(ptr, type, member)
#define list_entry_is_head(pos, head, member) \
(&pos->member == (head))
#define list_first_entry(ptr, type, member) \
list_entry((ptr)->next, type, member)
#define list_next_entry(pos, member) \
list_entry((pos)->member.next, typeof(*(pos)), member)
#define list_for_each(pos, head) \
for (pos = (head)->next; !list_is_head(pos, (head)); pos = pos->next)
#define list_for_each_entry(pos, head, member) \
for (pos = list_first_entry(head, typeof(*pos), member); \
!list_entry_is_head(pos, head, member); \
pos = list_next_entry(pos, member))
#define list_for_each_entry_safe(pos, n, head, member) \
for (pos = list_first_entry(head, typeof(*pos), member), \
n = list_next_entry(pos, member); \
!list_entry_is_head(pos, head, member); \
pos = n, n = list_next_entry(n, member))
#define my_list_for_each_entry(pos, head, member) \
for (pos = container_of((head)->next, typeof(*pos), member); &(pos)->member != head; \
pos = container_of((pos)->member.next, typeof(*pos), member))
static inline int list_is_head(const struct list_head *list,
const struct list_head *head)
{
return list == head;
}
static inline void __list_add(struct list_head *new,
struct list_head *prev,
struct list_head *next)
{
next->prev = new;
new->next = next;
new->prev = prev;
prev->next = new;
}
static inline void list_add(struct list_head *new, struct list_head *head)
{
__list_add(new, head, head->next);
}
static inline void list_add_tail(struct list_head *new, struct list_head *head)
{
__list_add(new, head->prev, head);
}
static inline void __list_del(struct list_head *prev, struct list_head *next)
{
next->prev = prev;
prev->next = next;
}
static inline void __list_del_entry(struct list_head *entry)
{
__list_del(entry->prev, entry->next);
}
static inline void list_del(struct list_head *entry)
{
__list_del_entry(entry);
}
LIST_HEAD(head);
struct SAMPLE {
int a;
struct list_head link;
};
int main(void)
{
struct SAMPLE *ps, *ps_node, *ps_temp, *ps_del, *ps_insert;
struct list_head *lh;
for (int i = 0; i < 10; ++i) {
if ((ps = (struct SAMPLE *)malloc(sizeof(struct SAMPLE))) == NULL) {
fprintf(stderr, "cannot allocate memory!...\n");
exit(EXIT_FAILURE);
}
ps->a = i;
list_add_tail(&ps->link, &head);
if (i == 5)
ps_del = ps;
if (i == 7)
ps_insert = ps;
}
list_for_each(lh, &head) {
ps = container_of(lh, struct SAMPLE, link);
printf("%d ", ps->a);
}
printf("\n");
list_del(&ps_del->link);
list_for_each(lh, &head) {
ps = container_of(lh, struct SAMPLE, link);
printf("%d ", ps->a);
}
printf("\n");
if ((ps = (struct SAMPLE *)malloc(sizeof(struct SAMPLE))) == NULL) {
fprintf(stderr, "cannot allocate memory!...\n");
exit(EXIT_FAILURE);
}
ps->a = 100;
list_add(&ps->link, &ps_insert->link);
list_for_each(lh, &head) {
ps = container_of(lh, struct SAMPLE, link);
printf("%d ", ps->a);
}
printf("\n");
ps_temp = NULL;
list_for_each_entry_safe(ps, ps_node, &head, link) {
free(ps_temp);
ps_temp = ps;
}
return 0;
}
3.5. Eski Çekirdek Sürümlerindeki list.h Dosyası
Çekirdeğin eski sürümlerinde list.h dosyası oldukça sade idi. Sonra bu dosyanın içeriğinde de bazı
faydalı değişiklikler yapıldı. Ancak bu değişiklikler veri yapısının anlaşılmasını da biraz zorlaştırmıştır.
Örneğin 2.2.26 çekirdeğindeki list.h dosyası oldukça sade bir biçimde aşağıdaki gibi oluşturulmuştur:
/* 2.2.26 <list.h> dosyasının içeriği */
#ifndef _LINUX_LIST_H
#define _LINUX_LIST_H
#ifdef __KERNEL__
/*
* Simple doubly linked list implementation.
*
* Some of the internal functions ("__xxx") are useful when
* manipulating whole lists rather than single entries, as
* sometimes we already know the next/prev entries and we can
* generate better code by using them directly rather than
* using the generic single-entry routines.
*/
struct list_head {
struct list_head *next, *prev;
};
#define LIST_HEAD_INIT(name) { &(name), &(name) }
#define LIST_HEAD(name) \
struct list_head name = { &name, &name }
#define INIT_LIST_HEAD(ptr) do { \
(ptr)->next = (ptr); (ptr)->prev = (ptr); \
} while (0)
static __inline__ void __list_add(struct list_head *new,
struct list_head *prev,
struct list_head *next)
{
next->prev = new;
new->next = next;
new->prev = prev;
prev->next = new;
}
static __inline__ void list_add(struct list_head *new, struct list_head *head)
{
__list_add(new, head, head->next);
}
static __inline__ void list_add_tail(struct list_head *new, struct list_head *head)
{
__list_add(new, head->prev, head);
}
static __inline__ void __list_del(struct list_head *prev,
struct list_head *next)
{
next->prev = prev;
prev->next = next;
}
static __inline__ void list_del(struct list_head *entry)
{
__list_del(entry->prev, entry->next);
}
static __inline__ int list_empty(struct list_head *head)
{
return head->next == head;
}
static __inline__ void list_splice(struct list_head *list,
struct list_head *head)
{
struct list_head *first = list->next;
if (first != list) {
struct list_head *last = list->prev;
struct list_head *at = head->next;
first->prev = head;
head->next = first;
last->next = at;
at->prev = last;
}
}
#define list_entry(ptr, type, member) \
((type *)((char *)(ptr)-(unsigned long)(&((type *)0)->member)))
#define list_for_each(pos, head) \
for (pos = (head)->next; pos != (head); pos = pos->next)
#endif /* __KERNEL__ */
#endif
3.6. Arama Algoritmaları ve Sözlük Tarzı Veri Yapıları
Arama işlemleri bir anahtar (key) eşliğinde yapılmaktadır. Anahtar bulunması istenen varlığı temsil etmektedir. Örneğin pek çok kişinin bilgileri bir veri yapısında tutuluyor olabilir. Biz de ismini bildiğimiz bir kişiyi bu veri yapısında arayabiliriz. Burada anahtar isimdir. Veri yapıları dünyasında anahtar-değer çiftlerini tutan ve anahtar verildiğinde ona karşı gelen değerin elde edilmesini sağlayan veri yapılarına genel olarak sözlük (dictionary) tarzı veri yapıları denilmektedir.
Elemanların sıralı olmadığı liste tarzı veri yapılarında elemanların tek tek gözden geçirilmesi yoluyla yapılan aramalara sıralı arama (sequential search) denilmektedir. Sıralı arama oldukça yavaş bir yöntemdir. Sıralı aramada listedeki eleman sayısı N olmak üzere anahtarın bulunması için ortalama N/2 kez karşılaştırmanın yapılması gerekmektedir. Bu tür algoritmaların karmaşıklığına Big O notasyonunda O(N) karmaşıklık denildiğini anımsayınız. Ancak ne olursa olsun eleman sayısının makul olduğu bir durumda sıralı arama en iyi yöntem haline de gelebilmektedir. Örneğin en fazla 20 civarında elemanın bulunduğu bir durumda bu elemanları diziye yerleştirip sıralı bir biçimde aramak en etkin yöntem haline gelebilmektedir.
Eğer elemanlar sıralıysa ve herhangi bir elemana erişim çok hızlı (buna rastgele erişim de denilmektedir) yapılabiliyorsa ikili arama (binary search) en iyi yöntemdir. İkili aramanın algoritmik karmaşıklığı O(log N) biçimindedir. Aslında ikili aramanın daha genel bir biçimine enterpolasyon araması (interpolation search) denilmektedir. Enterpolasyon aramasında bölme ortadan değil daha uygun yerlerden yapılmaktadır. Ancak enterpolasyon araması dizi dağılımının bilindiği ve özellikle de dizinin düzgün dağıldığı durumlarda faydalı bir etki oluşturmaktadır. Diziyi önce sıraya dizip sonra ikili arama uygulamak ise genellikle iyi bir fikir değildir. Çünkü sırayı korumak için araya eleman ekleme ve aradan eleman silme gibi işlemlerde O(N) karmaşıklıkta kaydırmaların yapılması gerekmektedir.
3.6.1. İndeksli Arama
Peki ideal bir anahtar-değer araması nasıl olabilir? Şüphesiz ideal durumda aramanın
O(1) karmaşıklıkta yapılması istenir. Anahtarın bir int değer olduğunu ve kişinin
numarasını belirttiğini düşünelim. Biz de numarasını bildiğimiz kişinin bilgilerini elde
etmek isteyelim. Örneğimizdeki kişilerin bilgileri PERSON isimli bir yapıyla temsil
edilmiş olsun:
struct PERSON {
...
};
struct PERSON türünden büyük bir dizi açabiliriz:
struct PERSON people[MAX_SIZE];
Sonra da kişilerin numaralarını indeks yaparak bu diziye yerleştirebiliriz. Örneğin numarası 123 olan kişinin bilgilerini diziye şöyle yerleştirebiliriz:
people[123] = person_info;
Artık numarası 123 olan bu kişinin bilgilerini O(1) karmaşıklıkta aşağıdaki gibi elde edebiliriz:
person_info = people[123];
Bu yöntem ilk bakışta çok iyi bir yöntem gibi gözükse de genellikle kullanılabilir bir
yöntem değildir. Çünkü burada anahtar int türdendir. Ancak uygulamalarda anahtarlar
farklı türlerden olabilmektedir. Örneğin anahtar kişinin adı soyadı olabilir. Ad ve soyad
gibi yazısal bilgiler indeks belirtmemektedir. Bu yöntemin diğer bir sakıncası da
anahtarların yüksek basamaklı sayılardan oluşabildiği durumlarda dizilerin çok fazla yer
kaplamasıdır. Örneğin TC kimlik numarasının anahtar yapılarak kişilerin bilgilerinin elde
edilmesinin istendiği bir durumu düşünelim. TC kimlik numarası 11 basamaklı bir sayıdır.
Yani skalası 100 milyarlık sınırdadır. 100 milyarlık bir yapı dizisini bu amaçla oluşturmak
mümkün olmayabilir, mümkün olsa da etkin olmayabilir. Bu yönteme indeksli arama (index
search) denilmektedir. Ancak çok özel durumlarda bu yöntem uygun bir yöntem olarak
kullanılabilmektedir.
3.7. Hash Tabloları
Algoritmik aramalarda en çok kullanılan yöntemlerden biri hash tabloları (hash tables) denilen yöntemdir. Hash tabloları aslında yukarıda belirttiğimiz indeksli arama ile sıralı aramanın hibrit bir biçimi gibidir. Yöntemde ismine hash tablosu (hash table) denilen makul uzunlukta bir dizi oluşturulur. Sonra anahtarlar ismine hash fonksiyonu (hash function) denilen bir fonksiyona sokularak dizi indeksine dönüştürülür. Sonra da dizinin o indeksteki elemanına başvurulur. Örneğin kişilerin bilgilerini TC kimlik numaralarına göre saklayıp geri almak isteyelim. Hash tablomuzun uzunluğu da 1000 olsun. Hash fonksiyonumuzun da “1000’e bölümden elde edilen kalan” değerini veren fonksiyon olduğunu varsayalım. Bu durumda örneğin 2566198712 TC kimlik numarasına sahip kişinin bilgileri hash tablosunun 712’nci indeksteki elemanında saklanacaktır. 72484926820 TC kimlik numarasına sahip kişinin bilgileri de dizinin 820’nci indeksteki elemanında saklanacaktır. Ancak farklı kişilerin TC kimlik numaraları hash fonksiyonuna sokulduğunda aynı indeks değerleri de elde edilebilecektir. Örneğin 6238517712 TC kimli numarasına sahip kişi de dizinin 712’nci indeksteki elemanına yerleşmek isteyecektir. İşte hash tablosu yönteminde bu duruma çakışma (collision) denilmektedir. Hash tablosu yöntemi çakışma durumunda izlenecek stratejiye göre çeşitli alt kollara ayrılmaktadır.
3.7.1. Çakışma Çözümleme Stratejileri
Hash tabloları yönteminde çakışma durumunda bu sorunu çözmek için temel olarak iki alt yöntem grubu kullanılmaktadır: ayrı zincir oluşturma (separate chaining) yöntemi ve açık adresleme (open addressing) yöntemi. Açık adresleme yöntemi de kendi aralarında doğrusal yoklama (linear probing), karesel yoklama (quadratic probing), çift hash’leme (double hashing) gibi alt yöntemlere ayrılmaktadır. Ayrı zincir oluşturma ve açık adresleme yöntemlerinin dışında başka çakışma çözümleme stratejileri de vardır. Ancak ağırlıklı olarak bu stratejiler tercih edilmektedir.
Not
Linux çekirdeklerindeki tüm hash tablolarında ayrı zincir oluşturma (separate chaining) alt yöntemi tercih edilmiştir.
3.7.1.1. Ayrı Zincir Oluşturma (Separate Chaining)
Ayrı zincir oluşturma (separate chaining) yönteminde hash tablosu aslında bir bağlı liste dizisi gibi oluşturulur. Yani hash tablosunun her elemanı bağlı listenin ilk elemanını (head pointer) gösteren bir gösterici durumundadır. Anahtar hash fonksiyonuna sokulur, bir indeks elde edilir ve o indeksteki bağlı listenin hemen önüne (ya da duruma göre arkasına) eklenir. Eleman aranırken anahtar yine aynı hash fonksiyonuna sokulur ve dizinin ilgili indeksindeki bağlı listede sıralı arama yapılır.
Hash tablolarına eleman insert etmek O(1) karmaşıklıktadır. Tabii burada kullanılacak hash fonksiyonu da önemlidir. Küçük döngüler içeren hash fonksiyonları O(1) karmaşıklığı yükseltmemektedir. Elemanın silinmesi de O(1) karmaşıklıkta yapılabilmektedir. Eleman aramanın O(1) karmaşıklıkta yapılabilmesi için bağlı listelerdeki zincir uzunluklarının uzun olmaması gerekir. Örneğin yukarıda 10 kadar eleman için en hızlı arama yönteminin sıralı arama olduğunu söylemiştik. Bu koşul sağlandığında sıralı aramanın O(1) karmaşıklıkta olduğu söylenebilir. O halde eğer zincirlerdeki ortalama eleman makul bir düzeyde tutulursa arama işlemi de O(1) karmaşıklıkta yapılabilecektir. Ancak hash tablosu küçük fakat tabloya eklenecek eleman fazla ise bu durumda hash tablosu yöntemi artık sıralı arama yöntemine benzer hale gelir. Yani bu yöntemin en kötü durumdaki (worst case) karmaşıklığının O(N) olduğu söylenebilir.
Tabii hash tablosu yöntemini kullanan kişiler sistem hakkında bazı ön bilgilere sahip olursa tabloyu uygun bir büyüklükte oluşturabilirler. İşletim sistemi gibi yüksek performans isteyen sistemlerde hash tablolarının zincirlerinin ortalama 1 civarında tutulması uygun olabilmektedir. Hash tabloları da duruma göre büyütülebilmektedir. Ancak büyütmenin önemli bir zaman maliyeti vardır. Yeni bir hash tablosunun tahsis edilmesi; eski tablodaki elemanların yeniden hash’lenerek yeni tabloya yerleştirilmesi uzun zaman alan bir işlemdir. İşletim sistemlerinin çekirdeklerinde bu biçimde uzun zaman alacak işlemler tercih edilmez. Bu nedenle Linux çekirdeğindeki hash tabloları büyütülmemektedir.
Hash tablolarında tablo elemanlarına (zincirlere değil) İngilizce bucket (kova), tablodaki toplam eleman sayısının bucket sayısına bölümüne de yükleme faktörü (load factor) denilmektedir. İdeal yükleme faktörünün <= 1 olduğunu söyleyebiliriz.
Sözlük tarzı veri yapılarında genel olarak aynı anahtara ilişkin birden fazla anahtar-değer çifti veri yapısına yerleştirilememektedir. (Bazı kütüphanelerde buna izin verilebilmektedir.) Eğer aynı anahtara ilişkin yeni bir değer insert edilmeye çalışılırsa eski değer yeni değerle yer değiştirilmektedir. Bazı tasarımlar ise aynı anahtara ilişkin insert yapmayı engellemektedir. Yani bu tasarımlarda yalnızca olmayan elemanlar tabloya insert edilebilmektedir. Linux çekirdeğindeki hash tablolarında anahtarlar birbirinden farklı olmak zorundadır.
3.7.1.2. Açık Adresleme ve Doğrusal Yoklama
Her ne kadar Linux çekirdeğindeki hash tablolarında ayrı zincir oluşturma (separate chaining) stratejisi kullanılıyorsa da burada açık adresleme (open addressing) stratejisi hakkında da küçük bir açıklama yapmak istiyoruz.
Açık adresleme yöntemi de kendi arasında yoklama (probing) biçimine göre çeşitli alt yöntemlere ayrılmaktadır. Açık adreslemenin en yaygın ve basit biçimi doğrusal yoklama (linear probing) denilen biçimidir.
Doğrusal yoklama oldukça basit bir fikre dayanmaktadır. Bu yöntemde yine bir hash tablosu oluşturulur. Ancak hash tablosunda bağlı listelerin adresleri tutulmaz; bizzat değerlerin kendisi tutulur. Tabloya eleman ekleneceği zaman yine anahtardan bir hash değeri elde edilir. Doğrudan değer tablonun hash ile elde edilen indeksine yerleştirilir. Başka bir anahtar aynı hash değerini verdiğinde (yani çakışma durumu oluştuğunda) o indeksten itibaren boş yer bulunana kadar yan yana indekslere sırasıyla bakılır. Örneğin hash olarak 123 değerini elde etmiş olalım. Tablonun 123’üncü elemanının dolu olduğunu düşünelim. Bu durumda 124’üncü elemanına bakarız. O da doluysa 125’inci elemanına bakarız. Ta ki boş bir indeks bulunana kadar. Değeri ilk boş indekse yerleştiririz.
Bu yöntemde arama işlemi de benzer biçimde yapılmaktadır. Yani aranacak elemanın hash değeri elde edilir. O indekse başvurulur. Anahtar o indekste değilse anahtar bulunana kadar ya da boş bir kova (bucket) görülene kadar yan yana diğer indekslere bakılır.
Anahtara dayalı eleman silme de benzer biçimde yapılmaktadır. Ancak eleman silindiğinde ilgili kovanın (bucket) boşaltılması arama işlemlerinde sorunlara yol açabilecektir. Burada yöntemlerden biri silinen elemana ilişkin kovanın boş yapılmayıp silinmenin özel bir değerle belirtilmesidir. Örneğin her kova için bir durum bayrağı tutulabilir. Bu durum bayrağı ilgili kovanın dolu olduğunu, boş olduğunu ya da silinmiş olduğunu belirtebilir. Böylece arama sırasında silinmiş kovalar görüldüğünde durulmaz. İlk boş kova görüldüğünde durulur. Tabii silinmiş kovalara yeni elemanlar eklenebilir.
3.7.1.3. Hash Fonksiyonlarının Tasarımı
Peki hash tablolarında kullanılacak iyi bir hash fonksiyonu nasıl olmalıdır? İyi bir hash fonksiyonunun hızlı olması gerekir. Çünkü insert gibi arama gibi işlemlerde hash fonksiyonu kullanılacaktır. İyi bir hash fonksiyonunun anahtarlar yanlı bile olsa tabloya onları iyi bir biçimde yaydırabilmesi gerekir. Örneğin aslında sayısal anahtarlar için “bölümden elde edilen kalan” iyi bir hash fonksiyonu değildir.
Hash tablolarında tablonun asal sayı uzunluğunda olması hash fonksiyonlarının daha iyi yaydırmasına yardımcı olmaktadır. (Örneğin tablo uzunluğu için 100 yerine 101 değeri tercih edilebilmektedir.) Hash fonksiyonları sayıyı indekse dönüştüren ve yazıyı indekse dönüştüren fonksiyonlar biçiminde oluşturulabilir. Hash tablolarının 2’nin kuvveti uzunluğunda alınması hash fonksiyonlarının daha hızlı çalışmasına da yol açabilmektedir. (Örneğin bölümden elde edilen kalan yerine bit düzeyinde öteleme işlemleri hız kazancı sağlayabilmektedir.) Linux çekirdeklerinde hash tabloları için genellikle sayfa katlarında (yani 4096’nın katlarında) alanlar tahsis edilmektedir.
3.8. Linux Çekirdeğinde Hash Tablosu Gerçekleştirimi
Şimdi de Linux çekirdeğindeki hash tablosu gerçekleştirimi üzerinde duralım. Linux kaynak
kodlarında hash tablosuna ilişkin yapılar ve fonksiyonlar bağlı listelere ilişkin yapıların
ve fonksiyonların bulunduğu başlık dosyasında tanımlanmıştır. Yani hash tabloları için ayrı
bir başlık dosyası oluşturulmamıştır. RCU’suz hash tablolarının gerçekleştirimi
include/linux/list.h dosyası içerisinde, RCU’lu hash tablolarının gerçekleştirimi ise
include/linux/rculist.h dosyası içerisinde bulunmaktadır. Ancak her iki gerçekleştirim
de aynı yapıları kullanmaktadır.
3.8.1. hlist_head ve hlist_node Yapıları
Ayrı zincir oluşturma yönteminde hash tablosundaki kovaların (buckets) aslında bağlı
listelerin ilk düğümünün yerini tutan göstericilerden oluştuğunu belirtmiştik. Linux
çekirdeklerinde bağlı listenin kök düğümü de eleman düğümleri de list_head yapısıyla
temsil ediliyordu. Ancak ayrı zincir oluşturmalı hash tablolarındaki kovalarda (buckets)
bağlı listenin son düğümünün yerinin tutulmasına gerek yoktur. Elemanlar hemen listenin
başına eklenebilir. Arama da listenin başından itibaren yapılabilir. Tabii performans
bakımından bağlı liste düğümlerinin yine çift bağlı (doubly linked) olması gerekir. Çünkü
adresini bildiğimiz bir düğümü hash tablosundan kolaylıkla çıkartabiliriz. O halde çekirdek
tablolarında kök düğümde tek gösterici, eleman düğümlerinde ise çift gösterici
bulunmalıdır.
Çekirdekte kullanılan hash tablosu gerçekleştiriminde kök düğüm hlist_head yapısıyla
temsil edilmiştir:
struct hlist_head {
struct hlist_node *first;
};
Görüldüğü gibi yapıda tek bir gösterici vardır. O da zincirdeki ilk elemanı göstermektedir.
Zincirdeki bağlı listenin düğümleri de hlist_node yapısıyla temsil edilmiştir:
struct hlist_node {
struct hlist_node *next, **pprev;
};
Buradaki düğüm yapısını listelerdeki düğüm yapısı ile karşılaştırınız:
struct list_head {
struct list_head *next, *prev;
};
Hash tablosundaki düğümlerin pprev elemanı önceki düğümün adresini değil önceki
düğümdeki next elemanının adresini göstermektedir. Bu nedenle pprev göstericiyi
gösteren göstericidir. Hash tablolarındaki düğümlerde geri gitmek için bir neden yoktur.
Ancak eleman silme durumunda bu tasarım önceki elemanın next göstericisinin daha kolay
güncellenmesine yol açmaktadır. Örneğin p göstericisi bir hlist_node düğümünü
gösteriyor olsun. Biz de bu düğümü silecek olalım. Burada önceki düğümün next elemanının
sileceğimiz düğümün next elemanındaki düğümü göstermesi sağlanmalıdır. Bu işlem pratik
olarak şöyle yapılabilmektedir:
*p->pprev = p->next;
Halbuki düğümler list_head yapısıyla temsil ediliyor olsaydı bu işlem ancak şöyle
yapılabilirdi:
p->prev->next = p->next;
Görüldüğü gibi bu güncellemede fazladan bir işlem yapılmaktadır. hlist_node tasarımının
diğer önemli bir faydası da bu tasarımda kök düğüm için özel bir işlemin yapılmasına gerek
kalmamasıdır. Yani listeye ilk kez eleman eklerken *p->pprev kök düğümün next
göstericisi haline gelecektir. Heterojen yapılarda bu tür güncellemelerin yapılması daha
fazla çabayı gerektirmektedir.
Peki neden bütün çift bağlı listelerde bu teknik kullanılmıyor? hlist_node yapısında
olduğu gibi prev göstericisi önceki düğümün başlangıç adresini göstermek yerine neden
önceki düğümün next göstericisini göstermiyor? İşte geriye doğru ilerlemenin gerekli
olabildiği durumlarda bu tasarımda geriye gidiş zorlaşmaktadır. Ancak yukarıda da
belirttiğimiz gibi hash tablolarındaki zincirlerde zaten geriye gitmenin bir anlamı yoktur.
3.8.2. Hash Tablolarının Oluşturulması
Peki biz yukarıdaki hlist_head ve hlist_node yapılarını kullanarak hash tablosunu
nasıl oluşturabiliriz? İşte yapılacak ilk şey hlist_head yapısı türünden bir dizi tahsis
etmektir. Örneğin biz bu işlemi kullanıcı modunda aşağıdaki gibi simüle edebiliriz:
#include <stdio.h>
#include <stdlib.h>
#define TABLE_SIZE 4096
struct hlist_head {
struct hlist_node *first;
};
struct hlist_node {
struct hlist_node *next, **pprev;
};
int main(void)
{
struct hlist_head *hash_table;
if ((hash_table = (struct hlist_head *)malloc(
sizeof(struct hlist_head) * TABLE_SIZE)) == NULL) {
fprintf(stderr, "cannot allocate memory!...\n");
exit(EXIT_FAILURE);
}
/* ... */
free(hash_table);
return 0;
}
Çekirdekteki list.h dosyası içerisinde hash tablosuna eleman eklemek için çeşitli basit
fonksiyonlar bulundurulmuştur. Tabii hlist_node düğümleri de aslında başka yapıların
elemanı durumunda olacaktır. Yine asıl yapı nesnesinin adresi container_of makrosuyla
elde edilecektir.
Başlangıçta hlist_head yapısındaki first elemanı NULL değerinde olmalıdır.
Bunun için list.h içerisinde makrolar bulundurulmuştur:
#define HLIST_HEAD_INIT { .first = NULL }
#define HLIST_HEAD(name) struct hlist_head name = { .first = NULL }
#define INIT_HLIST_HEAD(ptr) ((ptr)->first = NULL)
Örneğin:
for (int i = 0; i < TABLE_SIZE; ++i)
INIT_HLIST_HEAD(&hash_table[i]);
Zincirlerdeki son düğümün next elemanı da NULL değerindedir. Böylece arama
NULL görmeyene kadar ilerlenerek yapılabilmektedir.
Tablodaki zincirlerin önüne eleman eklemek için hlist_add_head fonksiyonu
bulundurulmuştur:
static inline void hlist_add_head(struct hlist_node *n, struct hlist_head *h)
{
struct hlist_node *first = h->first;
WRITE_ONCE(n->next, first);
if (first)
WRITE_ONCE(first->pprev, &n->next);
WRITE_ONCE(h->first, n);
WRITE_ONCE(n->pprev, &h->first);
}
Fonksiyonun birinci parametresi eklenecek yeni düğümün adresini, ikinci parametresi ise kök
düğüm nesnesini belirtmektedir. Buradaki WRITE_ONCE atamayı volatile erişimle
yapmaktadır. WRITE_ONCE(a, b) çağrısını a = b gibi düşünebilirsiniz.
3.8.3. Hash Tablosundan Düğüm Silme
Hash tablosundan bir düğüm silmek için hlist_del fonksiyonu kullanılmaktadır. Fonksiyon
list.h içerisinde şöyle tanımlanmıştır:
static inline void hlist_del(struct hlist_node *n)
{
__hlist_del(n);
n->next = LIST_POISON1;
n->pprev = LIST_POISON2;
}
Burada asıl silme işlemini yapan fonksiyon __hlist_del fonksiyonudur. Düğüm silindikten
sonra silinen düğümün next ve pprev göstericilerine güvenlik amacıyla özel değerler
atandığını görüyorsunuz. Bu özel değerler geçerli adresler belirtmemektedir. Eğer silinen
düğüm yanlışlıkla kullanılırsa page fault oluşmasına yol açacaktır. __hlist_del
fonksiyonu da şöyle tanımlanmıştır:
static inline void __hlist_del(struct hlist_node *n)
{
struct hlist_node *next = n->next;
struct hlist_node **pprev = n->pprev;
WRITE_ONCE(*pprev, next);
if (next)
WRITE_ONCE(next->pprev, pprev);
}
Zincirdeki son düğümün next göstericisinde NULL adres bulunmalıdır. Fonksiyonun
içerisinde bu durumun kontrol edildiğine ve ilk düğümün silinmesinin özel bir durum
oluşturmadığına dikkat ediniz.
3.8.4. Insert Fonksiyonları
Çok fazla gereksinim olmasa da zincirdeki belli bir düğümün önüne ve arkasına düğüm insert
eden hlist_add_before ve hlist_add_behind fonksiyonları da bulundurulmuştur:
static inline void hlist_add_before(struct hlist_node *n,
struct hlist_node *next)
{
WRITE_ONCE(n->pprev, next->pprev);
WRITE_ONCE(n->next, next);
WRITE_ONCE(next->pprev, &n->next);
WRITE_ONCE(*(n->pprev), n);
}
static inline void hlist_add_behind(struct hlist_node *n,
struct hlist_node *prev)
{
WRITE_ONCE(n->next, prev->next);
WRITE_ONCE(prev->next, n);
WRITE_ONCE(n->pprev, &prev->next);
if (n->next)
WRITE_ONCE(n->next->pprev, &n->next);
}
3.8.5. Hash Tabloları için Döngü Makroları
Hash tablosundaki bir hlist_node adresi bilindiğinde onun içinde bulunduğu asıl yapının
adresinin container_of makrosu ile elde edilebildiğini biliyorsunuz. Ancak tıpkı bağlı
listelerde olduğu gibi hash tablolarında da bunun için container_of makrosu ile aynı
işlemi yapan bir entry makrosu bulundurulmuştur:
#define hlist_entry(ptr, type, member) container_of(ptr, type, member)
Hash tablosundaki bir zinciri dolaşmak için hlist_for_each döngü makrosu
kullanılmaktadır:
#define hlist_for_each(pos, head) \
for (pos = (head)->first; pos ; pos = pos->next)
Makronun ilk parametresi hlist_node türünden bir göstericiyi, ikinci parametresi ise
bağlı liste zincirinin başlangıç düğümüne ilişkin hlist_head nesnesinin adresini
almaktadır. Bu döngü makrosunun next elemanı NULL olmayana kadar ilerleme
sağladığına dikkat ediniz. Döngü her yinelendikçe birinci parametreye girilen göstericinin
içerisine zincirdeki sonraki düğümün adresi yerleştirilmektedir. Bu döngü makrosuyla zincir
dolaşılırken döngünün her yinelenmesinde asıl yapı nesnesinin değil onun içerisindeki
hlist_node nesnesinin adresinin elde edildiğine da dikkat ediniz. Bu adresten hareketle
container_of ya da hlist_entry makrolarıyla asıl nesnenin başlangıç adresinin elde
edilmesi gerekir. İşte bu iki işlemi aynı anda yapan hlist_for_each_entry isimli bir
döngü makrosu da bulundurulmuştur:
#define hlist_for_each_entry(pos, head, member) \
for (pos = hlist_entry((head)->first, typeof(*(pos)), member); \
pos; \
pos = hlist_entry((pos)->member.next, typeof(*(pos)), member))
Bu makronun artık birinci parametresi doğrudan asıl yapı türünden bir göstericiyi, ikinci
ve üçüncü parametreler sırasıyla bağlı listenin hlist_head adresini ve asıl yapıdaki
bağ elemanının ismini almaktadır.
Yukarıdaki makroda bir noktaya dikkatinizi çekmek istiyoruz. Hash tablosundaki
hlist_head kök düğümünün first elemanında NULL adres varsa yukarıdaki
hlist_for_each_entry makrosu tanımsız davranışa yol açar. İşte eğer first elemanı
NULL ise bu durumu ele alıp dolaşımı sonlandıran hlist_for_each_entry_safe döngü
makrosu da bulundurulmuştur:
#define hlist_for_each_entry_safe(pos, n, head, member) \
for (pos = hlist_entry_safe((head)->first, typeof(*pos), member); \
pos && ({ n = pos->member.next; 1; }); \
pos = hlist_entry_safe(n, typeof(*pos), member))
Makronun birinci parametresi asıl yapı nesnesi türünden göstericiyi, ikinci parametresi
hlist_node türünden göstericiyi, üçüncü parametresi hlist_head türünden kök düğümün
adresini, dördüncü parametresi de asıl yapıdaki bağ düğümünün ismini almaktadır. Bu
makronun hlist_for_each_entry makrosundan tek farkı zincir boşsa bir soruna yol açmadan
döngünün sonlanmasını sağlamasıdır. Döngü makrosunun içerisinde hlist_entry_safe
makrosunun kullanıldığına dikkat ediniz. Bu makro zincirin sonundaki NULL adresi de
dikkate almaktadır:
#define hlist_entry_safe(ptr, type, member) \
({ typeof(ptr) ____ptr = (ptr); \
____ptr ? hlist_entry(____ptr, type, member) : NULL; \
})
list.h dosyası içerisinde hash tablolarına ilişkin başka yararlı fonksiyonlar da vardır.
Bu fonksiyonları ileride gerektiğinde açıklayacağız. Bunları siz de inceleyebilirsiniz.
Bir hash tablosunun tamamen yok edilmesi için yalnızca hash tablosunun değil onun tüm zincirlerdeki elemanlarının da serbest bırakılması gerekir. Çekirdekte genel olarak böyle bir gereksinim yoktur.
3.8.6. Hash Tablosu Gerçekleştirimine Bir Örnek
Aşağıda list.h içerisindeki hash tablosu işlemleri için kullanıcı modunda çalıştırılabilecek
bir örnek verilmiştir. Örnekte TABLE_SIZE uzunluğunda her bir elemanı hlist_head türünden
olan bir dizi oluşturulmuştur:
if ((hash_table = (struct hlist_head *)malloc(sizeof(struct hlist_head) * TABLE_SIZE)) == NULL) {
fprintf(stderr, "cannot allocate memory!...\n");
exit(EXIT_FAILURE);
}
Sonra bu hlist_head elemanlarına ilkdeğer verilmiştir. (Yani onların first göstericilerine
NULL adres yerleştirilmiştir):
for (int i = 0; i < TABLE_SIZE; ++i)
INIT_HLIST_HEAD(&hash_table[i]);
Ondan sonra hash tablosuna rastgele 100 eleman eklenmiştir. Ancak bunun yanı sıra belli bir eleman da listeye ayrıca eklenmiştir:
struct PERSON {
char name[32];
int no;
struct hlist_node hlink;
};
/* ... */
for (int i = 0; i < 100; ++i) {
if ((per = (struct PERSON *)malloc(sizeof(struct PERSON))) == NULL) {
fprintf(stderr, "cannot allocate memory!...\n");
exit(EXIT_FAILURE);
}
if (i == 50) {
strcpy(per->name, "ALI SERCE");
per->no = 12345678;
}
else
set_random_person(per);
hash = hash_func(per->no);
hlist_add_head(&per->hlink, &hash_table[hash]);
}
Sonra liste dolaşılmıştır. Program biterken de tüm hash tablosu zincirleriyle birlikte serbest bırakılmıştır:
{
struct PERSON *per, *temp;
struct hlist_node *node;
for (int i = 0; i < TABLE_SIZE; ++i) {
temp = NULL;
hlist_for_each_entry_safe(per, node, &hash_table[i], hlink) {
free(temp);
temp = per;
}
free(temp);
}
free(hash_table);
}
Bağlı liste düğümleri serbest bırakılırken sonraki düğümün adresini saklamak gerekir. NULL
adrese free uygulamanın bir soruna yol açmayacağını anımsayınız. Aşağıda örneği bir bütün olarak veriyoruz:
#include <stdio.h>
#include <stddef.h>
#include <stdlib.h>
#include <string.h>
#include <time.h>
#define TABLE_SIZE 4096
struct hlist_head {
struct hlist_node *first;
};
struct hlist_node {
struct hlist_node *next, **pprev;
};
#define HLIST_HEAD_INIT { .first = NULL }
#define HLIST_HEAD(name) struct hlist_head name = { .first = NULL }
#define INIT_HLIST_HEAD(ptr) ((ptr)->first = NULL)
#define WRITE_ONCE(a, b) ((a) = (b)) /* bize özgü */
#define LIST_POISON1 (struct hlist_node *)0x00100100
#define LIST_POISON2 (struct hlist_node **)0x00200200
static inline void hlist_add_head(struct hlist_node *n,
struct hlist_head *h)
{
struct hlist_node *first = h->first;
WRITE_ONCE(n->next, first);
if (first)
WRITE_ONCE(first->pprev, &n->next);
WRITE_ONCE(h->first, n);
WRITE_ONCE(n->pprev, &h->first);
}
static inline void __hlist_del(struct hlist_node *n)
{
struct hlist_node *next = n->next;
struct hlist_node **pprev = n->pprev;
WRITE_ONCE(*pprev, next);
if (next)
WRITE_ONCE(next->pprev, pprev);
}
static inline void hlist_del(struct hlist_node *n)
{
__hlist_del(n);
n->next = LIST_POISON1;
n->pprev = LIST_POISON2;
}
#define container_of(ptr, type, member) ({ \
void *__mptr = (void *)(ptr); \
((type *)(__mptr - offsetof(type, member))); })
#define hlist_entry(ptr, type, member) \
container_of(ptr, type, member)
#define hlist_entry_safe(ptr, type, member) \
({ typeof(ptr) ____ptr = (ptr); \
____ptr ? hlist_entry(____ptr, type, member) : NULL; \
})
#define hlist_for_each(pos, head) \
for (pos = (head)->first; pos ; pos = pos->next)
#define hlist_for_each_safe(pos, n, head) \
for (pos = (head)->first; pos && ({ n = pos->next; 1; }); \
pos = n)
#define hlist_for_each_entry(pos, head, member) \
for (pos = hlist_entry((head)->first, typeof(*(pos)), member); \
pos; \
pos = hlist_entry((pos)->member.next, typeof(*(pos)), member))
#define hlist_for_each_entry_safe(pos, n, head, member) \
for (pos = hlist_entry_safe((head)->first, typeof(*pos), member); \
pos && ({ n = pos->member.next; 1; }); \
pos = hlist_entry_safe(n, typeof(*pos), member))
/* Test code */
struct PERSON {
char name[32];
int no;
struct hlist_node hlink;
};
void set_random_person(struct PERSON *per);
unsigned int hash_func(unsigned int key);
int main(void)
{
struct hlist_head *hash_table;
struct PERSON *per;
unsigned int hash;
int no;
srand(time(NULL));
if ((hash_table = (struct hlist_head *)malloc(
sizeof(struct hlist_head) * TABLE_SIZE)) == NULL) {
fprintf(stderr, "cannot allocate memory!...\n");
exit(EXIT_FAILURE);
}
for (int i = 0; i < TABLE_SIZE; ++i)
INIT_HLIST_HEAD(&hash_table[i]);
for (int i = 0; i < 100; ++i) {
if ((per = (struct PERSON *)malloc(sizeof(struct PERSON))) == NULL) {
fprintf(stderr, "cannot allocate memory!...\n");
exit(EXIT_FAILURE);
}
if (i == 50) {
strcpy(per->name, "ALI SERCE");
per->no = 12345678;
}
else
set_random_person(per);
hash = hash_func(per->no);
hlist_add_head(&per->hlink, &hash_table[hash]);
}
/* hlist_for_each ile arama */
{
struct hlist_node *node;
struct PERSON *per_find;
printf("Person no:");
scanf("%d", &no);
hash = hash_func(no);
hlist_for_each(node, &hash_table[hash]) {
per_find = hlist_entry(node, struct PERSON, hlink);
if (per_find->no == no) {
printf("Found: %s, %d\n", per_find->name, per_find->no);
break;
}
}
if (node == NULL)
printf("cannot find...\n");
}
/* hlist_for_each_entry_safe ile arama */
{
struct PERSON *per_find;
struct hlist_node *node;
hash = hash_func(no);
hlist_for_each_entry_safe(per_find, node, &hash_table[hash], hlink) {
if (per_find->no == no) {
printf("Found: %s, %d\n", per_find->name, per_find->no);
break;
}
}
if (per_find == NULL)
printf("cannot find...\n");
}
/* Tüm tabloyu serbest bırakma */
{
struct PERSON *per, *temp;
struct hlist_node *node;
for (int i = 0; i < TABLE_SIZE; ++i) {
temp = NULL;
hlist_for_each_entry_safe(per, node, &hash_table[i], hlink) {
free(temp);
temp = per;
}
free(temp);
}
free(hash_table);
}
return 0;
}
void set_random_person(struct PERSON *per)
{
int i;
for (i = 0; i < 31; ++i)
per->name[i] = rand() % 26 + 'A';
per->name[i] = '\0';
per->no = rand() % 1000000;
}
unsigned int hash_func(unsigned int key)
{
key = (key ^ 61) ^ (key >> 16);
key = key + (key << 3);
key = key ^ (key >> 4);
key = key * 0x27d4eb2d;
key = key ^ (key >> 15);
return key % TABLE_SIZE;
}
Örnekte TABLE_SIZE uzunluğunda, her bir elemanı hlist_head türünden olan bir dizi
oluşturulmuştur. Sonra bu hlist_head elemanlarına ilk değer verilmiştir (yani onların
first göstericilerine NULL adres yerleştirilmiştir). Ondan sonra hash tablosuna
rastgele 100 eleman eklenmiştir; ancak bunun yanı sıra belli bir eleman (numarası 12345678
olan “ALI SERCE”) da listeye ayrıca eklenmiştir. Program biterken tüm hash tablosu
zincirleriyle birlikte serbest bırakılmıştır.
Not
Bağlı liste düğümleri serbest bırakılırken sonraki düğümün adresini saklamak gerekir.
NULL adrese free uygulamanın bir soruna yol açmayacağını anımsayınız.
3.9. RCU’lu Hash Tablosu Fonksiyonları
Linux çekirdeğine kilitsiz (lock-free) RCU mekanizması eklendiğinde tıpkı bağlı listelerde
olduğu gibi hash tablolarına da yukarıdaki fonksiyonların sonu _rcu ile biten RCU uyumlu
versiyonları eklenmiştir. Bu fonksiyonlar include/linux/rculist.h dosyası içerisindedir.
Bu dosyada yukarıda gördüğümüz hash tablosu fonksiyonlarının RCU mekanizmalı versiyonları
bulunmaktadır. Biz buradaki fonksiyonların yalnızca isimlerini vereceğiz. RCU mekanizması
başka bir başlık altında ele alınacaktır:
hlist_add_head_rcu
hlist_del_rcu
hlist_add_before_rcu
hlist_add_behind_rcu
hlist_for_each_entry_rcu
hlist_for_each_entry_srcu /* safe version */
hlist_first_rcu(head)
hlist_next_rcu(node)
hlist_pprev_rcu(node)
Bu RCU’lu fonksiyonlar tıpkı bağlı listelerde olduğu gibi birden fazla okuyan ancak tek bir
yazan taraf varsa beklemeye yol açmamaktadır. Tabii birden fazla yazan tarafın ayrıca bir
senkronizasyon nesnesiyle korunması gerekir. Bu makrolarla dolaşım yapılırken yine bağlı
listelerde olduğu gibi ilgili kod bloğunun başına ve sonuna rcu_read_lock ve
rcu_read_unlock çağrılarının yerleştirilmesi gerekmektedir.
Çekirdek tıpkı bağlı listelerde olduğu gibi pek çok yerde (ancak her yerde değil) hash tablolarıyla RCU mekanizması eşliğinde işlem yapmaktadır. Çekirdeğin RCU mekanizması eşliğinde işlem yaptığı yerlerde sizin de bu RCU’lu fonksiyonları kullanmanız gerekir.